

Kdenlive – melhor editor grátis de vídeo do mundo
28 de abril de 2018 | Autor: antonini
[Voltar]
Categoria(s): Informática |
Comente
[Voltar]
[singlepic id=2991 w= h= float=center]
Para resolver problema do PHPMYADMIN exibindo código fonte, instalar:
apt-get install php7.0-mysql php7.0-curl php7.0-json php7.0-cgi php7.0 libapache2-mod-php7
[Voltar]
Inicializar pelo CD/DVD-ROM em modo UEFI.
Na opção de instalação de drivers de terceiro, deixe marcado a opção, marque a opção desativar security boot e crie uma senha de recuperação.
Escolha “sim” em desmontar a partição
Escolha continuar no modo UEFI
Na instalação do Linux, escolher a opção avançada de instalação.
Escolher a partição do pendrive para instalação do sistema e deixar selecionado a instalação do GRUB no armazenamento eMMC
[Voltar]
fdisk -l
dd if=/dev/zero of=/boot/swap bs=1024 count=1024000
1024000+0 registros de entrada
1024000+0 registros de saída
1048576000 bytes (1,0 GB, 1000 MiB) copiados, 74,2398 s, 14,1 MB/s
ls
chmod 600 swap
mkswap swap
free -m
swapon swap
nano /etc/fstab
/boot/swap swap swap defaults 0 0
reboot
[Voltar]
Se o seu disco SSD diminuiu o desempenho depois de um tempo de uso, o comando TRIM pode ajudá-lo a manter ele sempre rápido.
Um comando Trim (geralmente escrita como TRIM) permite que um sistema operacional possa informar a uma unidade de estado sólido (SSD), que os blocos de dados não estão mais sendo usados e podem ser limpo internamente. Como a operação de baixo nível de SSDs difere significativamente de unidades de disco rígido, a forma típica em que sistemas operacionais lidam com operações como exclusões e formatações resultam na inesperada degradação progressiva do desempenho de operações de gravação em SSDs. O comando Trim ajuda a manter sua unidade de estado sólido (SSD) em sua velocidade máxima, pois ele permite que o SSD possa lidar com a sobrecarga do processo de limpeza do lixo, o que, de outra forma iria abrandar significativamente futuras operações de gravação para os blocos envolvidos, antecipadamente.
Para mais detalhes sobre o programa, acesse esse link.
Ativando e usando o TRIM em discos SSD no Ubuntu Linux
Para ativar e usar o TRIM em discos SSD no Ubuntu Linux, faça o seguinte:
Passo 1. Se não estiver aberto, execute um terminal usando o Dash ou pressionando as teclas CTRL+ALT+T;
Passo 2. Confirme se você tem um SSD como o comando abaixo. Se o resultado for 0 você tem um SSD, mas se for 1 que é um HDD:
cat /sys/block/sda/queue/rotational
Passo 3. Mesmo se você tiver um SSD, nem todos eles suportam o TRIM. Para saber se o seu suporta executado o comando a seguir:
sudo hdparm -I /dev/sda | grep “TRIM supported”
Passo 4. Se o retorno for igual a mensagem abaixo, então você pode seguir adiante. Se não houver nenhuma saída, isso significa que seu SSD não suporta TRIM.
Data Set Management TRIM supported
Passo 5. Agora execute o comando, conforme abaixo:
sudo fstrim -v /
Passo 6. Você deve ver uma saída, parecida com isso:
/: 87781376 bytes were trimmed
Passo 7. Se tudo correu bem, é hora de programar o cron para executar o fstrim uma vez por dia, para isso, crie um arquivo com esse comando:
gksudo gedit /etc/cron.daily/trim
Passo 8. Copie e cole as linhas abaixo no arquivo criado e salve-o. Em seguida, feche o gedit:
#!/bin/sh
LOG=/var/log/trim.log
echo “*** $(date -R) ***” >> $LOG
fstrim -v / >> $LOG
fstrim -v /home >> $LOG
Passo 9. Agora torne o script executável com o comando abaixo:
sudo chmod +x /etc/cron.daily/trim
Pronto. Agora seu sistema está com o TRIM habilitado.
[Voltar]
dd if=arquivo.img of=arquivo.iso
[Voltar]
o arquivo de configuração é o /etc/ssh/sshd_conf:
nano /etc/ssh/sshd_conf
Procure por “Port” e altere para:
Port 10022
Salve e saia do arquivo.
Agora só falta reiniciar o daemon do ssh:
/etc/init.d/ssh restart
Para entrar no servidor digitar:
ssh -p10022 pi@192.168.1.5
ou
ssh -p10022 pi@antonini.psc.br
[Voltar]
[Voltar]
O Raspberry Pi usa o script dphys-swapfile para gerenciar o swap. A imagem padrão inclui o script ativado por padrão. O arquivo de configuração localiza-se em /etc/dphys-swapfile. O único parâmetro do arquivo é CONF_SWAPSIZE=100, que cria ou configura 100MB de swap em /var/swap. Como descrito acima, colocar o swapfile em /var não é uma boa ideia proque o diretório fica no cartão SD. Voce pode mudar a localização do arquivo com o comando CONF_SWAPFILE=/<localização que você quer>, como por exemplo, /etc/dphys-swapfile
Para mudar o tamanho do swap:
/etc/init.d/dphys-swapfile stop
nano /etc/dphys-swapfile
CONF_SWAPSIZE=100 mudar para CONF_SWAPSIZE=1024, ou outro valor.
/etc/init.d/dphys-swapfile start
dphys-swapfile swapon
Para mudar o swap de lugar:
/etc/init.d/dphys-swapfile stop
CONF_SWAPFILE=/<localização que você quer>
/etc/init.d/dphys-swapfile start
Referências:
[Voltar]
[Voltar]
[Voltar]
Raspberry Pi e o processo de boot
29/10/2012 – POR SERGIO PRADO
Categorias: Raspberry Pi Tags: arm11, bootloader, broadcom, gpu, Kernel, raspberry pi
Uma das primeiras coisas que você precisa fazer quando começar a trabalhar com uma nova plataforma de hardware é entender o seu processo de boot.
E o processo de boot da Raspberry Pi é um pouco diferente comparado às outras plataformas comuns que rodam Linux como a Beagleboard, Beaglebone ou i.MX53. A começar pelo hardware…
Quando você energiza o SoC da Broadcom (BCM2835), quem assume o controle não é a CPU (ARM1176JZ-F), mas sim a GPU, responsável pelo processamento gráfico do chip! Sim, caros leitores. Ao ser energizada, o processador principal da placa é a GPU, e o co-processador é o ARM11, que fica ali, paradinho, esperando sua vez para entrar na brincadeira.
Outra diferença é que a Raspberry Pi (pelo menos por enquanto) não usa o U-Boot como bootloader padrão para carregar e executar o kernel Linux. Mas vamos começar pelo começo…
O primeiro eletron
Conforme descrevi mais acima, ao energizar a Raspberry Pi, quem assume o controle da placa é o core da GPU. E o primeiro código a ser executado esta armazenado em ROM, dentro do SoC, inacessível a nós, meros mortais que não trabalhamos na Broadcom.
Este código é responsável por procurar um código de boot em algumas interfaces de armazenamento, carregar este código para uma memória interna (cache L2 do SoC para ser mais preciso) e executar. E que tipos de interfaces de armazenamento o SoC reconhece como dispositivo de boot? Não dá para saber, já que não temos o datasheet do SoC. Temos disponível apenas uma parte do datasheet, que descreve o acesso aos periféricos do SoC, mas que não descreve o processo de boot (este documento pode ser acessado aqui). Mas se você quiser o datasheet do BCM2835 é fácil, é só assinar um NDA com a Broadcom…:)
Voltando ao processo de boot, o que sabemos é que o SoC procura na primeira partição do cartão SD um arquivo chamado bootcode.bin. Esta partição do cartão SD precisa estar formatada com FAT32, e o bootcode.bin é um código compilado para ser executado na GPU. Sim, você adivinhou, não temos os fontes deste bootloader de primeiro estágio… :(
Resumindo a primeira etapa de boot: você liga a Raspberry Pi, a GPU assume, procura o arquivo bootcode.bin na primeira partição do cartão SD, carrega para a memória cache L2 e executa.
Mas o que então faz este bootcode.bin?
O segundo estágio
O bootcode.bin tem duas responsabilidades principais: inicializar a SDRAM e carregar um bootloader de segundo estágio para ela. Este bootloader de segundo estágio é um arquivo chamado start.elf que também deve estar na primeira partição do cartão SD.
O start.elf também é um binário compilado para ser executado na GPU, e com a ajuda de um outro binário chamado fixup.dat, também possui duas responsabilidades principais: configurar o hardware de acordo com um arquivo de configuração e carregar o kernel Linux.
O arquivo de configuração é chamado config.txt, e também deve estar na primeira partição do cartão SD. Neste arquivo de configuração você pode configurar o hardware, definir mapeamento de memória, especificar parâmetros para carregar o kernel Linux, etc. Uma especificação completa do arquivo encontra-se aqui.
Após ler o arquivo de configuração, ele irá carregar o arquivo kernel.img, que também deve estar na primeira partição do cartão SD. Esse arquivo nada mais é do que a imagem do kernel Linux. Antes de executar a imagem do kernel, ele é capaz de passar a linha de comandos para o kernel, que pode ser definida no arquivo cmdline.txt, ou em uma variável no arquivo config.txt.
Resumo da ópera: você energiza a placa, a GPU assume, carrega o bootcode.bin para a memória cache L2 e executa. O bootcode.bin inicializa a SDRAM, carrega o start.elf para a RAM externa e executa. O start.elf configura o hardware de acordo com o arquivo config.txt, carrega a imagem do kernel em kernel.img, lê a linha de comandos do kernel no cmdline.txt, e dá vida ao pinguim mais famoso do universo. Todos estes arquivos devem estar na primeira partição do cartão SD, que deve estar formatado com FAT32:
$ ls /media/raspberrypi
bootcode.bin cmdline.txt config.txt fixup.dat kernel.img start.elf
Obs: Em uma versão mais antiga do firmware de boot, existia um passo adicional. Em vez do bootcode.bin carregar diretamente o start.elf, ele carregava o loader.bin, e este era o responsável por carregar o start.elf. Este passo adicional foi removido nas versões mais novas do firmware do boot.
O firmware
Todo o firmware descrito aqui, com exceção da imagem do kernel (kernel.img) pode ser baixado no repositório oficial do projeto no github em https://github.com/raspberrypi/firmware. Mas nada de fontes, você só vai encontrar neste projeto os binários e alguma documentação, o suficiente para você carregar e executar o seu sistema Linux na Raspberry Pi.
No próximo artigo vamos construir um sistema Linux do zero para a Raspberry Pi. Até lá!
Um abraço,
Sergio Prado
[Voltar]
Opa! Dica rápida para quem precisa utilizar algo plugado nas entradas USB dos hosts em uma VM, no VirtualBox.
1° Passo: Instale o pacote VirtualBox Extension Pack: Downloads – Oracle VM VirtualBox
2° Passo: Adicione seu usuário no grupo do VirtualBox:
usermod SEU_USER -a -G vboxusers
3° Passo: Reinicie a sua máquina.
4° Passo: Vá em configurações da sua VM e habilite as duas opções:
5° Passo: espete o dispositivo USB à VM, clicando no ícone de USB com sinal de mais na parte direita.
No Linux Minth:
Após a instalação do VirtualBox no seu Linux, siga as instruções abaixo, para habilitar as portas USB para a(s) máquina(s) virtual(is).

.: No Linux Mint 17 clique no Menu clique na ícone Configurações do Sistema;

.: Na caixa de diálogo Configurações do Sistema role a barra de rolagem até o final e, em Administração cllique em Usuários e Grupos, nesse momento será solicitado sua senha root.;

.: Na caixa de diálogo Usuários e Grupos selecione seu usuário e, a sua direita, no final do box, irá aparecer os grupos aos quais seu usuário faz parte. Clique sobre os Grupos;

.: No box que abre localize e marque o grupo vboxusers e clique em OK;

.: Agora, em Grupos aparece o grupo vboxusers;

.: Feche todos os programas abertos e reinicie a seção do Linux.

.: Após o reinício do sistema, coloque o pendriver na porta USB. Abra o VirtualBox e inicie um sistema operacional previamente instalado. Se ainda não instalou um sistema, este é o momento.
.: Com a máquina virtual aberta, neste exemplo, Windows XP, clique no menu do Virtualbox > Dispositivos > Dispositivos USB e selecione o(s) dispositivo(s) que quer habilitar.

Nas distribuições Linux derivadas do Debian, adicione o Grupo VBOXUSERS ao seu usuário: usermod SEU_USER -a -G vboxusers
[Voltar]
08/01 – Começa inventário de Patrimônio pela Ebserh
Prezados Membros da Subcomissão do CHC
Conforme já informado nas nossas últimas reuniões, a Ebserh iniciará um inventário dos bens móveis visando a cessão dos mesmos – tal ato atende ao que consta no Contrato assinado entre a EBSERH e a UFPR. Para tanto, a Ebserh realizou licitação e contratou uma empresa especializada chamada Integrade, Soluções de Informática, Controle Patrimonial e Avaliações Ltda.
A função dos membros da Subcomissão do CHC neste Inventário da Ebserh é apenas de auxiliar os funcionários contratados da Integrade, informando onde ficam os locais da Unidade e abrindo os armários que por ventura os bens estejam guardados.
Informo que as pessoas contratadas pela Integrade deverão realizar o trabalho sozinhas, verificando os bens e os cadastrando em equipamento próprio da empresa.
Tal inventário iniciará no dia 08/01/2018, pela Maternidade Victor Ferreira do Amaral, depois se estenderá para as casas externas e por fim chegará no prédio central e seus anexos.
Comunico que este Inventário será realizado por Unidades.
Desta forma, acredito que teremos previsibilidade do tempo utilizado no trabalho e o agendamento nas Unidades evitando não atrapalhar a rotina de trabalho dos locais.
Ressalto que sempre antes de iniciar os trabalhos em uma Unidade, a mesma será informada com antecedência.
Boas festas a todos e um 2018 de muita saúde, alegria e bençãos!!!
Att.
Vanessa Massambani
Chefe da Unidade de Patrimônio do CHC/UFPR – EBSERH
Telefone: 3208-6504 – vanessa.massambani@hc.ufpr.br – patrimonio@hc.ufpr.br
[Voltar]
Novo dispositivo do tamanho de uma moeda permite encontrar o seu carro através do seu celular.

Alguma vez você já passou pela situação de ter estacionado o carro e depois esquecer onde o deixou? Isso acontece com todo mundo: achar uma vaga o mais rápido possível porque está atrasado, e na hora de ir embora você não lembra mais onde o carro está.
Ou talvez alguma vez que você já estava pronto para sair de casa, só não conseguia encontrar as chaves do seu apartamento ou do carro… E aí você passa os próximos 15 minutos revirando sua casa a procura das benditas chaves, que muitas vezes estão no último lugar que você pensa em procurar.
Se você já se encontrou em alguma dessas situações, fique tranquilo. Alguns dos maiores problemas da vida estão desaparecendo por causa de novas tecnologias, e esse é mais um deles. Graças a um novo dispositivo, você não precisa mais de um GPS caríssimo para rastrear o seu veículo, e pode localizar os seus pertences imediatamente através do seu smartphone.
Acaba de ser lançado no mercado brasileiro um pequeno dispositivo que, com a ajuda do seu smartphone, permite localizar seu carro, chaves, carteira, bolsa e até o próprio celular, caso você o perca.
Do que se trata?
Esse novo dispositivo se chama RastreR. Pequeno e discreto, o RastreR já revolucionou o mercado de rastreamento no exterior e agora está disponível também no Brasil.

Mas e como funciona?
O RastreR é muito fácil de usar, em menos de cinco minutos você terá seus pertences protegidos. É só baixar o aplicativo gratuito (disponível tanto para iPhone quanto para Android) e conectar o dispositivo conforme as instruções.
Feito isso, basta colocar o RastreR dentro do seu carro, ou junto das chaves de casa, na sua carteira ou bolsa, ou até no seu bichinho de estimação. Além de registrar a última localização onde estava conectado, o RastreR também pode ser usado como um alarme para caso algo saia do seu alcance – sendo útil para se proteger contra furtos ou mesmo o seu esquecimento.
Outras funções
De acordo com o fabricante, o RastreR é usado também por aquelas pessoas que vivem esquecendo onde deixaram a carteira, as chaves e até mesmo o celular. É também útil para encontrar a sua bagagem, bicicleta ou qualquer outro item pessoal.
Para aqueles que possuem filhos ou também um animal de estimação, o RastreR também é uma forma eficiente de ser alertado caso eles resolvam se afastar muito de você.
[Voltar]
Neste artigo apresento o UltraDefrag, um defragmentador de partições NTFS para GNU/Linux.
[ Hits: 1.241 ]
Por: Eduardo Mozart de Oliveira em 10/12/2017 | Blog: http://www.eduardomozartdeoliveira.wordpress.com/
Introdução
Durante a manutenção de um notebook de cliente, após realizar a manutenção preventiva (exclusão de arquivos temporários, atualização de programas), decidi realizar a desfragmentação de disco. Apesar do Windows acompanhar um desfragmentador de disco nativo, uso o Auslogic Disk Defrag que, apesar de não ser Open Source, é gratuito para uso doméstico e comercial. Durante a desfragmentação, o programa realizou uma análise no meu disco rígido externo (que uso para manutenção e backup) e constatou alta fragmentação de disco. Como precisava finalizar o chamado, realizei a desfragmentação apenas no disco do cliente, porém, decidi realizar a desfragmentação em meu próprio computador, que possui o Deepin 15.5 Beta (baseado no Debian “Sid” x86_64).
Mas, afinal, o que é fragmentação? A fragmentação ocorre quando um arquivo não é salvo de forma contínua no disco. “Como assim?” A imagem abaixo demonstra um disco rígido fragmentado [2]:
 Figura 1: Fragmentação de arquivos (FAT)
Figura 1: Fragmentação de arquivos (FAT)Fonte: Make Tech Easier, 2015.
Note que, um mesmo arquivo, ocupa diversos setores do disco, não sendo salvos de forma contínua. Isto é extremamente comum no Windows, devido a forma como o sistema de arquivos aloca os arquivos. [2]
O sistema de arquivos EXT aloca arquivos de uma maneira mais inteligente. Ao invés de salvar cada arquivo próximos uns dos outros no disco, ele mantém uma quantidade de espaço livre entre eles. Quando um arquivo é editado e precisa crescer, há espaço para que ele cresça. [3]
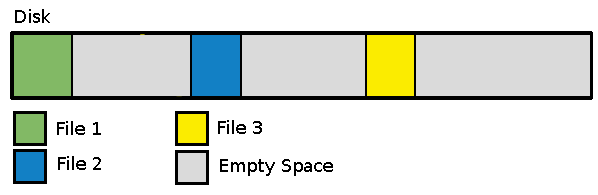 Figura 2: Alocação de arquivos (Linux)
Figura 2: Alocação de arquivos (Linux)Fonte: Make Tech Easier, 2015.
Sejamos justos: O NTFS possui uma lógica similar (de manter uma certa quantidade de espaço livre após o arquivo) [2], porém, se ocorrer fragmentação no sistema de arquivos EXT, ele tentará mover os arquivos próximos para reduzir a fragmentação em uso normal, sem a necessidade de um utilitário de desfragmentação. [3]
A fragmentação pode ocorrer no Linux, principalmente em partições que possuem mais de 80% de espaço ocupado. [3] Se você possui problemas com fragmentação no Linux, provavelmente você precisa obter um disco maior.
Apesar de não acompanhar um desfragmentador nativo, é possível instalar o pacote ”e2fsprogs” através do apt-get (Debian), que adiciona o utilitário ”e4defrag” ao sistema. [3]
Infelizmente, para desfragmentar partições NTFS no Linux, não há soluções prontas.
Há um truque para alcançar a desfragmentação NTFS no Linux. Você precisará de um segundo HDD ou pelo menos 51% de espaço (se não estiver usando compressão – leia abaixo). [4]
O truque é usar ferramentas para “clonar” a partição. O fsarchive “clona” uma partição NTFS, mas ao restaurar, ele não restaura os arquivos onde eles estavam, salvando os arquivos sem fragmentação. [4]
Porém, há um aviso importante a aqueles que pensam que o NTFS pode ser desfragmentado no Linux simplesmente copiando arquivos [4]:
Alguns arquivos/diretórios possuem um atributo especial ativo, chamado Compressão. [4]
Toda vez que o Linux (cp, fsarchiver etc) escreve um arquivo/diretório em um sistema de arquivos NTFS, ele o escreve sem compressão NTFS, independente da compressão de arquivos/diretórios estar habilitada ou não. [4]
Então, você pode encontrar-se em uma situação que, ao restaurar com fsarchive (ou cp etc) você preencherá a partição e não terá espaço suficiente. [4]
Alguns tipos de dados podem alcançar uma taxa de compressão NTFS de 3, então você pode possuir uma partição de X GB e a soma destes arquivos ser cerca de 3*X em tamanho. [4]
Porém, pesquisando na Internet, pude encontrar um //port// do UltraDefrag (um desfragmentador Open Source para Windows) para Linux, que usa a biblioteca NTFS-3G (disponível para diversos sistemas operacionais, como Linux, FreeBSD, Mac OS X, Solaris etc) para desfragmentar e otimizar partições NTFS. [5] Atualmente, há uma versão de testes (Beta) apenas para console. [6]
Use o UltraDefrag por sua própria conta e risco. Tenha em mente que o UltraDefrag para Linux é beta (em testes).
Eu testei em meu disco rígido USB externo, e ele parece fazer um bom trabalho em sistemas de arquivos NTFS. Não tive corrupção de dados até agora.
Mas: recomendo FORTEMENTE que você não use-o em uma partição Windows e em sua partição de boot. Ele poderá quebrar a inicialização do Windows. Não por corromper os arquivos, mas por que o NTFS requer que alguns arquivos estejam em determinados setores – especialmente se a partição é usada para iniciar o Windows. Desfragmentadores para Linux podem não se importar com arquivos de sistema, por que para o Linux são apenas arquivos comuns. [5]
O “UltraDefrag for Linux” pode ser baixado aqui
Ele é nomeado “ultradefrag-5.0.0AB.7.zip”.
Eu encontrei alguns problemas ao tentar compilar o UltraDefrag do código-fonte. O arquivo README.linux (localizado no diretório ultradefrag-5.0.0AB.7/src) possui algumas instruções para compilação, testes e a sintaxe de linha de comandos do UltraDefrag. Há algumas informações importantes que precisam ser lidas ANTES de iniciar a compilação:
“Não há atualmente nenhum script “configure” para adaptar o arquivo Makefile para seu ambiente. Você precisará adaptá-lo, apesar do arquivo “Makefile” provido servir para a maioria dos casos, após adaptar as localizações dos arquivos de cabeçalho e objetos compartilhados da libntfs-3g.”
De acordo com a documentação, pode ser necessário adaptar o arquivo Makefile para que ele possa encontrar as bibliotecas necessárias do NTFS-3G no sistema e possa realizar a compilação do UltraDefrag. As variáveis que o README refere-se são as variáveis LIB1 e LIB2 (linha 26 e 27 do arquivo ultradefrag-5.0.0AB.7/src/Makefile).
Após editar as variáveis, criei um diff das alterações, criando um arquivo de patch que altera os arquivos ultradefrag-5.0.0AB.7/src/Makefile e ultradefrag-5.0.0AB.7/src/wincalls/ntfs-3g.c para que eles possam ser compilados no Debian “Sid”.
Você pode encontrar o arquivo de patch no SourceForge aqui
Caso o link direto não funcione, você pode obter o arquivo de patch aqui
Aqui está o procedimento completo:
sudo apt-get update
$ sudo apt-get upgrade install ntfs-3g-dev libncurses5-dev libncursesw5-dev gcc-multilib
$ wget http://jp-andre.pagesperso-orange.fr/ultradefrag-5.0.0AB.7.zip
$ unzip ultradefrag-5.0.0AB.7.zip
$ wget https://sourceforge.net/p/ultradefrag/discussion/709673/thread/380cf1e6/07fe/attachment/udefrag.patch
$ patch -p 0 -i udefrag.patch
$ cd ultradefrag-5.0.0AB.7/src
$ make
$ sudo cp udefrag /usr/local/bin
Nas duas primeiras linhas, atualizamos a lista de pacotes de repositórios e baixamos as dependências de compilação do UltraDefrag. Em um segundo momento, baixamos o código-fonte do UltraDefrag e o extraímos. Depois, baixamos o arquivo de patch, adaptando o código para compilação no Deepin (Debian “Sid”) e o aplicamos. Em seguida, compilamos o código-fonte e copiamos o arquivo binário “udefrag” para /usr/local/bin, para que possamos executá-lo sem informar o caminho completo do binário (digitando apenas “udefrag” no Terminal).
Talvez o arquivo de patch não seja o ideal para seu ambiente ou falhe durante a aplicação. Não tem problema, podemos realizar as adaptações na mão, para que o UltraDefrag possa ser compilado em qualquer sistema que possui as bibliotecas necessárias (e não apenas no Debian “Sid”).
Primeiro, você precisa se certificar que seu sistema possui todas as dependências necessárias. No Debian “Sid”, elas são instaláveis através do apt-get, porém, o nome das dependências necessárias podem mudar de acordo com sua distribuição.
Para editar o arquivo ultradefrag-5.0.0AB.7/src/Makefile, você pode usar qualquer editor de sua preferência (como o Nano ou vi no Terminal ou o Gedit na interface gráfica). No Nano, pressionando “CTRL + W” é possível localizar texto em arquivos. O Gedit possui funcionalidade similar ao pressionar “CTRL + F”.
nano Makefile
A primeira coisa que você precisará alterar no arquivo ultradefrag-5.0.0AB.7/src/Makefile é o caminho das bibliotecas. Aparentemente, o Makefile do “UltraDefrag for Linux” foi adaptado para ser compilado no Red Hat por possuir, na linha 18 (LIB2), o caminho “/usr/lib/gcc/x86_64-redhat-linux/4.6.0”. Você precisará adaptar este caminho para a localização do gcc de acordo com seu sistema. Para descobrirmos o diretório do gcc, use os seguintes comandos:
cd /usr/lib/gcc
$ ls
aotcompile.py classfile.py i686-linux-gnu x86_64-linux-gnu
Note que a saída do comando informou dois diretórios: “i686-linux-gnu” e “x86_64-linux-gnu”. Caso tenha dúvida da arquitetura do seu sistema, use o comando:
uname -m
x86_64
Agora, juntando as peças do quebra-cabeça, temos o caminho: “/usr/lib/gcc/x86_64-linux-gnu”. Porém, esta informação, por si só, não é suficiente. Precisamos descobrir a versão do GCC disponível no sistema, que no arquivo Makefile original é “4.6.0”.
A comunidade Arch adaptou o Makefile para obter automaticamente a versão do GCC do sistema. [8] Abaixo da linha 20 (GCC), adicione a variável GCC_VERSION:
Você pode executar o comando no Terminal para certificar-se que o comando retornará a saída correta:
echo shell expr `gcc -dumpversion`
shell expr 6.4.0
Caso o comando falhe, você pode realizar o mesmo procedimento utilizado anteriormente para descobrir o nome do diretório “/usr/lib/gcc/x86_64-linux-gnu” para descobrir a versão do GCC:
cd /usr/lib/gcc/x86_64-linux-gnu/
$ ls
4.8 4.8.5 4.9 4.9.4 5 5.4.1 6 6.4.0 7 7.1.0
Após alterar o caminho das bibliotecas, recebia a seguinte mensagem de erro:
cd wincalls; make wincalls.a
make[1]: Entering directory /home/myuser/Desktop/ultradefrag-5.0.0AB.7/src/wincalls’ gcc -DLXGC=1 -O2 -I/usr/include/ntfs-3g -I/usr/include -I../include -I../dll/zenwinx -c ntfs-3g.c ntfs-3g.c: In function ‘ntfs_open’: ntfs-3g.c:147:27: error: ‘MS_RDONLY’ undeclared (first use in this function) vol = ntfs_mount(device,MS_RDONLY); ^ ntfs-3g.c:147:27: note: each undeclared identifier is reported only once for each function it appears in make[1]: *** [ntfs-3g.o] Error 1 make[1]: Leaving directory/home/myuser/Desktop/ultradefrag-5.0.0AB.7/src/wincalls’
make: *** [wincalls.a] Error 2
Este erro ocorre devido a variável “MS_RDONLY” não estar declarada. [8] O patch corrige este erro automaticamente. Mas podemos editar o arquivo ultradefrag-5.0.0AB.7/src/wincalls/ntfs-3g.c manualmente e adicionar, na linha 34 (acima de stdio.h), a linha:

Agora, ao tentar compilar o UltraDefrag, recebia as seguintes mensagens de erro:
ld: cannot find /usr/lib64/crt1.o: Arquivo ou diretório não encontrado
ld: cannot find /usr/lib64/crti.o: Arquivo ou diretório não encontrado
ld: cannot find /usr/lib/gcc/x86_64-linux-gnu/4.9.4/crtbegin.o: Arquivo ou diretório não encontrado
ld: cannot find /lib64/libntfs-3g.so.*.0.0: Arquivo ou diretório não encontrado
ld: cannot find -lgcc
Makefile:65: recipe for target ‘udefrag’ failed
Antes de partir desesperadamente tentando encontrar a origem da mensagem de erro on-line, podemos procurar os arquivos do sistema para nos certificarmos que os arquivos, de fato, estão ausentes em nosso sistema. Para isso, use o comando:
find /usr/ |grep crti.o
/usr/libx32/crti.o
/usr/lib/x86_64-linux-gnu/crti.o
/usr/lib32/crti.o
Para fins de performance, realizei a busca apenas em /usr/, mas é possível realizar a busca em todo sistema, substituindo “/usr/” por “/”. Note que a saída do comando retornou 3 arquivos que possuem este nome em /usr. Comparando os caminhos retornados com a saída do comando “make”, notamos que o compilador está buscando a dependência no local errado. Ao invés de procurá-la em “/usr/lib/x86_64-linux-gnu/”, ele está procurando-a em “/usr/lib64/crti.o”.
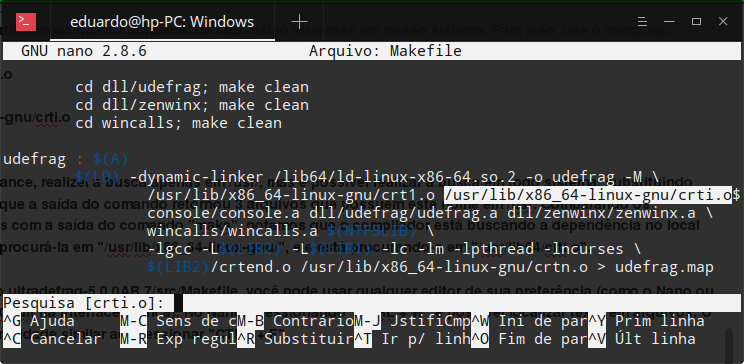
Ao encontrar a referência ao arquivo “crti.o”, atualizei o caminho da dependência de $(LIB1) para o caminho completo do arquivo (/usr/lib/x86_64-linux-gnu/). Realizei procedimento similar com as outras dependências que não foram encontradas.
Em relação ao erro de arquivo não encontrado “/lib64/libntfs-3g.so.*.0.0”, usei o comando “find” procurando por “libntfs-3g.so”:
find /usr |grep libntfs-3g.so
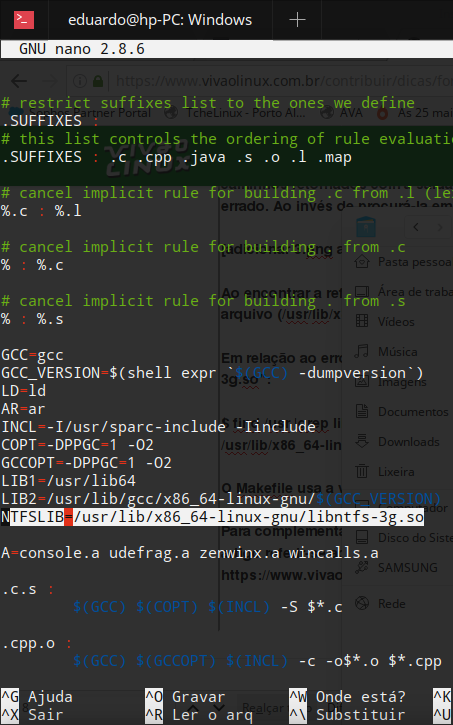
/usr/lib/x86_64-linux-gnu/libntfs-3g.so
O Makefile usa a variável NTFSLIB (linha 28) para referenciar a biblioteca “libntfs-3g.so”. Editei o conteúdo da variável para corresponder a biblioteca existente no sistema (/usr/lib/x86_64-linux-gnu/libntfs-3g.so) conforme a imagem abaixo:
Para complementar: há alguns anos, escrevi um artigo no Viva o Linux com instruções de compilação no CentOS (apesar do artigo referir-se ao pkg-config, é possível aplicar a mesma lógica para encontrar as dependências), que possuem instruções parecidas com as disponibilizadas no artigo que você está lendo agora, porém, com maiores detalhes e instruções voltadas ao CentOS: Como resolver problemas com o pkg-config [Artigo]
Agora, o UltraDefrag deve compilar normalmente, e você poderá usar o comando “cp” para copiar o binário “udefrag” para /usr/local/bin.
Você pode exibir a sintaxe do udefrag executando o comando sem argumentos no Terminal:
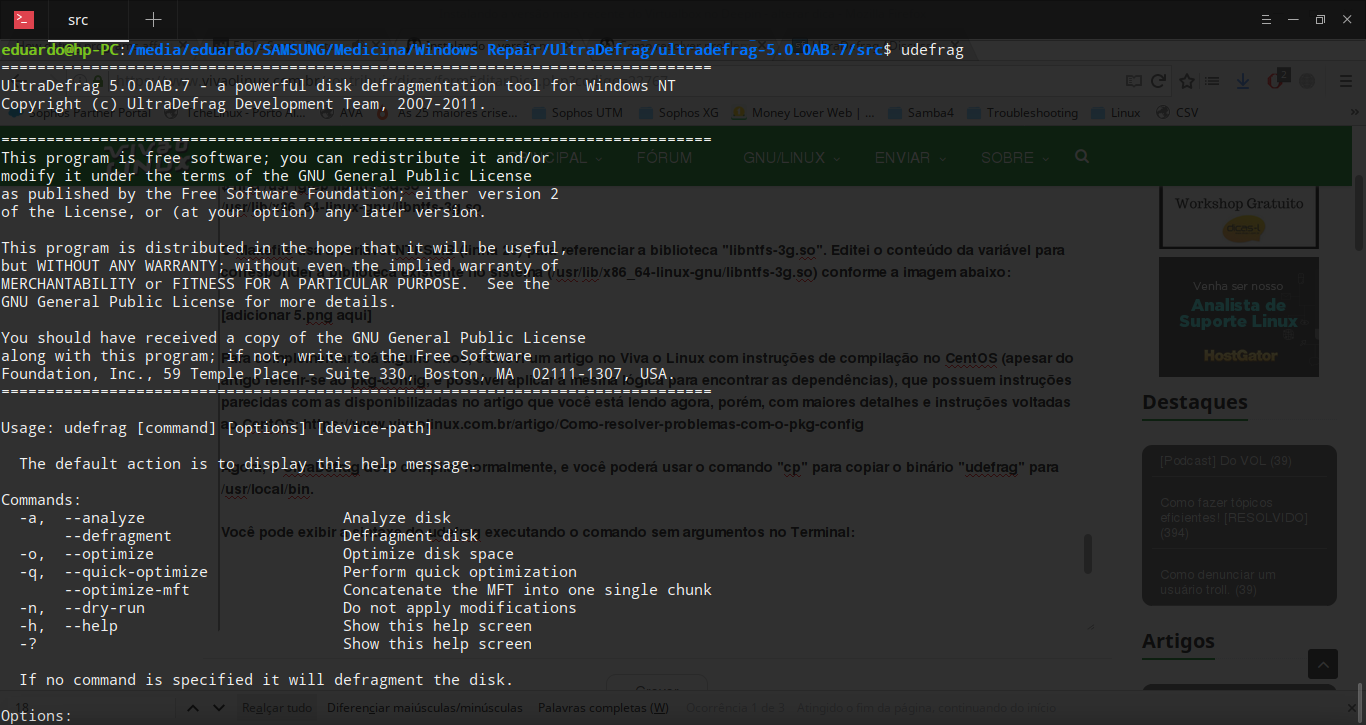
Basicamente, para iniciar a desfragmentação, a partição NTFS precisa estar desmontada. No Deepin, você pode desmontar a unidade através do explorador de arquivos ou no ícone disponível na barra de tarefas. Você também pode desmontar a unidade através do Terminal:
sudo fdisk -l
$ umount /dev/sdd1
O primeiro comando lista os discos disponíveis, e o segundo comando desmonta a partição.
Agora, para executar o UltraDefrag, execute o comando:
sudo ultradefrag /dev/sdd1
Você pode usar o comando “sudo fdisk -l” para descobrir o nome da partição (no caso, “sdd1”).
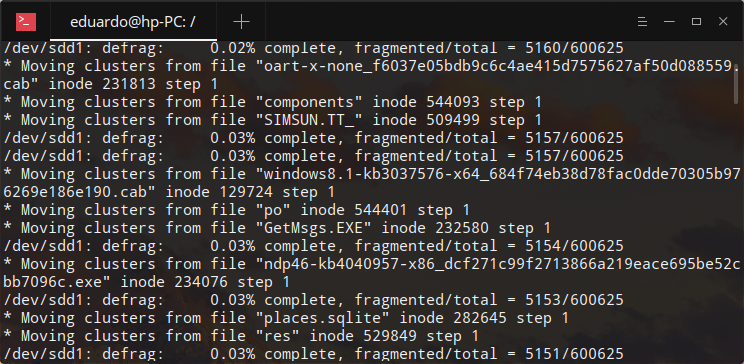
A desfragmentação começará. Em um HDD de 1 TB, a primeira desfragmentação levou 3 horas.
Conclusão
Apesar da extensão do artigo, a edição manual dos arquivos é necessária apenas se você encontrar erros durante a compilação e o patch não seja o suficiente.
O UltraDefrag possui outros recursos interessantes, atuando não apenas como desfragmentador, mas também como otimizador.
No início do disco rígido, as trilhas externas possuem maior taxa de transferências que trilhas internas. Alocar arquivos acessados frequentemente em trilhas externas aumenta a performance. [1] Além do UltraDefrag, o Auslogic Disk Defrag e MyDefrag para Windows também possuem esta funcionalidade. Porém, esta otimização pode ser demorada e não é realizada automaticamente, sendo necessário executá-la explicitamente no UltraDefrag:
sudo udefrag -o /dev/sdd1
Outro comando que o “UltraDefrag for Linux” possui e que é, no mínimo, interessante, é a exibição de um mapa do estado dos setores, exibindo setores em uso, fragmentados etc. similar ao disponibilizado pela interface gráfica do UltraDefrag para Windows:
sudo udefrag /dev/sdd1 -m
Referências
1. The Ultimate Defragger – LaRud’s Place. Larud.net. 2012. Disponível em: <http://www.larud.net/subtext/archive/2007/02/07/28.aspx> Acesso em: 22 de novembro de 2017.
2. How to Defragment Linux Systems. Make Tech Easier. 2015. Disponível em: <https://www.maketecheasier.com/defragment-linux/> Acesso em: 22 de novembro de 2017.
3. Why Linux Doesn’t Need Defragmenting. How-To Geek. 2016. Disponível em: <https://www.howtogeek.com/115229/htg-explains-why-linux-doesnt-need-defragmenting/> Acesso em: 22 de novembro de 2017.
4. Defragging NTFS Partitions from Linux. Ask Ubuntu. Disponível em: <https://askubuntu.com/questions/59007/defragging-ntfs-partitions-from-linux> Acesso em: 22 de novembro de 2017.
5. Defragment a NTFS partition from LINUX. Arch Linux Forums. Disponível em: <https://bbs.archlinux.org/viewtopic.php?id=125529> Acesso em: 22 de novembro de 2017.
6. Advanced NTFS-3G Features. Jean-Pierre André. 2017. Disponível em: <http://jp-andre.pagesperso-orange.fr/advanced-ntfs-3g.html> Acesso em: 22 de novembro de 2017.
7. Error compiling ultradefrag on Linux (Ubuntu). UltraDefrag (SourceForge). Disponível em: <https://sourceforge.net/p/ultradefrag/discussion/709673/thread/380cf1e6/?limit=25> Acesso em: 22 de novembro de 2017.
8. udefrag.patch. aur.git. Disponível em: <https://aur.archlinux.org/cgit/aur.git/tree/udefrag.patch?h=udefrag> Acesso em: 22 de novembro de 2017.
[Voltar]
Precisa juntar e dividir arquivos PDF? Para ajudá-lo nessa tarefa, veja como instalar o pdftk e o PDF Chain no Ubuntu.
Por Edivaldo – 20/12/2017
Se você trabalha com documentos, em algum momento precisará juntar e dividir arquivos PDF. Para ajudá-lo nessa tarefa, veja aqui como instalar o pdftk e o PDF Chain no Ubuntu.
PDFtk é uma ferramenta simples e multiplataforma de código aberto para manipular documentos PDF. pdftk é basicamente uma interface à biblioteca iText (compilada para código nativo usando GCJ), capaz de dividir, juntar, encriptar, decriptar, descomprimir, recomprimir, e reparar PDFs.
Também pode ser usado para manipular marcas-d’água, metadados, e para preencher formulários PDF com Dados FDF (Forms Data Format) ou Dados XFDF (XML Form Data Format).
Todas essas funções podem ser muito úteis no dia a dia, principalmente quando é preciso enviar arquivos PDF em e-mail e pegar algo dentro de um PDF (dividir) ou quando queremos montar algum documento com base em outros (juntar).
As outras funções, ficam por conta da sua necessidade e criatividade.
Como instalar o pdftk e o PDF Chain para juntar e dividir arquivos PDF no Ubuntu e seus derivados
Para para juntar e dividir arquivos PDF, primeiramente você precisa instalar o pdftk e o PDF Chain. Para isso, você deve fazer o seguinte:
Passo 1. Abra um terminal (no Unity use as teclas CTRL + ALT + T);
Passo 2. Se caso o pdftk ainda não estiver instalado, instale-o com este comando:
apt-get install pdftk
Passo 3. Para fazer o juntar arquivos PDF, utilize o comando conforme mostrado no exemplo abaixo, substituindo arquivox.pdf pelo nome dos arquivos que você quer unir, e arquivo_final.pdf, pelo nome de arquivo que você quer criar:
pdftk arquivo1.pdf arquivo2.pdf output arquivo_final.pdf
Passo 4. Agora para extrair páginas de um arquivo PDF, utilize o comando a seguir. Claro, substitua A1 pelo numero da página do arquivo PDF original. Por exemplo, se você quiser pegar a quinta página utilize A5. Se quiser um intervalo, como por exemplo da quarta até a sexta página, informe A4-6:
pdftk A=arquivo.pdf cat A1 output pagina1.pdf
Passo 5. Também é possível utilizar mais de um arquivo por vez e juntar em um único arquivo final, como no exemplo a seguir:
pdftk A=arquivo1.pdf B=arquivo1.pdf cat A1-7 B2 output arquivo_final.pdf
Passo 6. Embora trabalhar na linha de comando seja mais rápido e produtivo, se você preferir usar uma interface gráfica, use o comando a seguir para instalar o aplicativo PDF Chain;
sudo apt-get install pdfchain
Uma vez instalado, inicie o programa digitando no Dash 9ou em um terminal):pdfchain
O pdftk tem muitas outras funcionalidades, como a capacidade de rotacionar páginas, encriptar e decriptar arquivos, adicionar marcas d’água e muito mais.
Para conhecer todas as suas opções disponíveis, digite o seguinte comando:
pdftk –help
[Voltar]
